What is TensorRT? Overview & Use Case

TensorRT, short for Tensor Runtime, is a powerful tool from NVIDIA specifically designed to address sluggish performance when machine learning models are deployed in the real world.
By optimizing deep learning models for high-performance inference on NVIDIA GPUs, TensorRT can significantly improve the speed and efficiency of your applications.
What is TensorRT?
TensorRT is a high-performance deep learning inference library designed to help developers maximize the efficiency and deployment speed of their AI applications.
NVIDIA introduced TensorRT in 2017 as a response to the growing demand for fast and efficient inference in real-world applications powered by deep learning models.
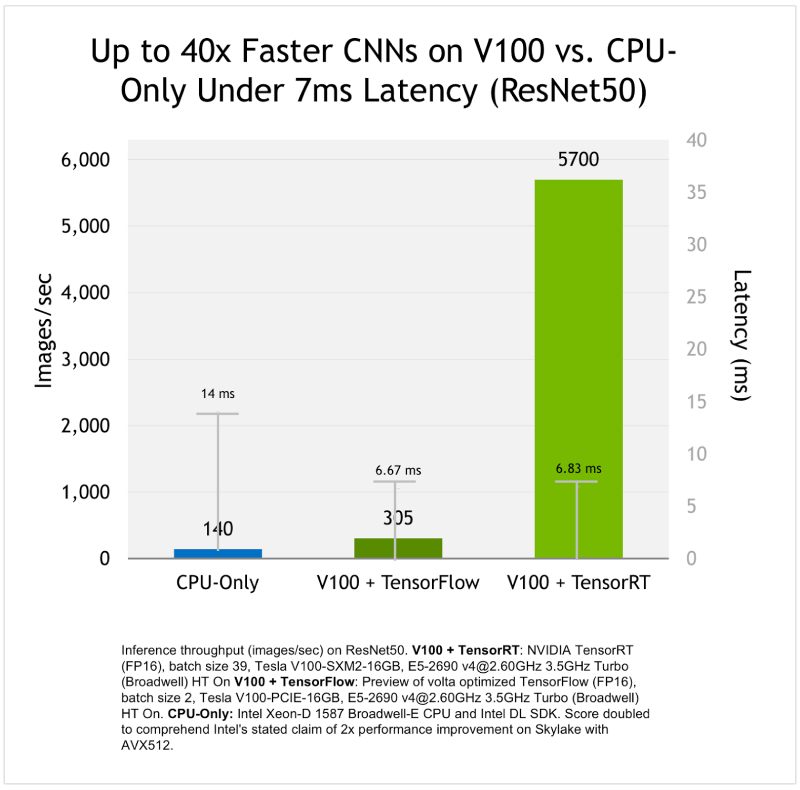
TensorRT achieves faster inference times, lower latency, and reduced computational costs, ultimately enhancing the performance of their machine learning models.
While frameworks like TensorFlow or PyTorch excel at training models, deploying them for real-time tasks can be computationally expensive.
This is where TensorRT shines.
TensorRT takes a pre-trained deep learning model and optimizes it specifically for running on NVIDIA GPUs. This optimization process involves techniques like quantization, which reduces the precision of the model's calculations without sacrificing significant accuracy.
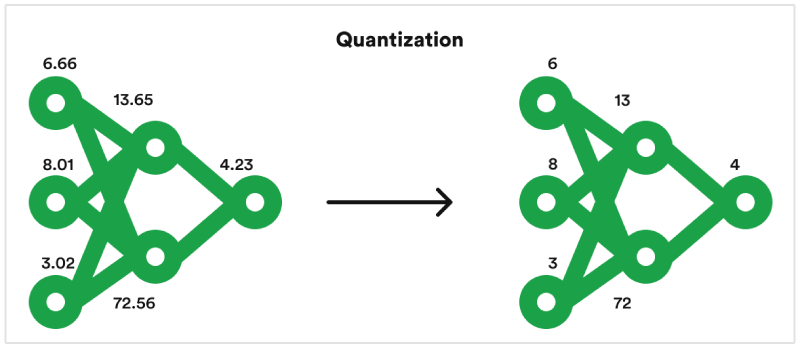
By streamlining the model for efficient execution on NVIDIA hardware, TensorRT unlocks significant performance gains, enabling your applications to run deep learning inferences much faster and with lower latency.
How TensorRT Works
TensorRT's power lies in its ability to transform a trained deep learning model into a lightning-fast inference engine specifically designed for NVIDIA GPUs.
Here’s a detailed look at the range of techniques TensorRT employs to achieve this optimization:
1. Layer Fusion
Layer fusion is a technique where multiple neural network layers are combined into a single operation.
This reduces the overhead associated with executing separate layers and improves computational efficiency. By fusing layers, TensorRT minimizes memory transfers and speeds up the processing of neural networks, resulting in faster inference times.
2. Precision Calibration
Precision calibration involves converting high-precision floating-point operations (FP32) into lower-precision formats like INT8 without significantly compromising accuracy.
This reduction in precision allows TensorRT to execute models more efficiently, as lower-precision computations require fewer resources. Precision calibration is particularly beneficial for deploying models on edge devices with limited computational power, as it reduces both memory usage and latency.
3. Kernel Auto-Tuning
Kernel auto-tuning is a process where TensorRT automatically selects the most efficient kernel (the core computation unit) for each operation within the neural network. By evaluating different kernel configurations, TensorRT identifies the optimal setup that maximizes performance on the target hardware.
This dynamic adjustment ensures that the model runs at peak efficiency, leveraging the full capabilities of the underlying GPU or other accelerators.
4. Dynamic Tensor Memory Management
Dynamic tensor memory management refers to the efficient allocation and deallocation of memory for tensors (multi-dimensional arrays) used during inference.
TensorRT dynamically manages memory resources to minimize fragmentation and ensure that memory is available when needed. This technique helps in reducing the overall memory footprint of the model, ensuring smooth operation even in memory-constrained environments.
TensorRT Use Case
Below are some key use cases where TensorRT has proven useful:
Autonomous Vehicles
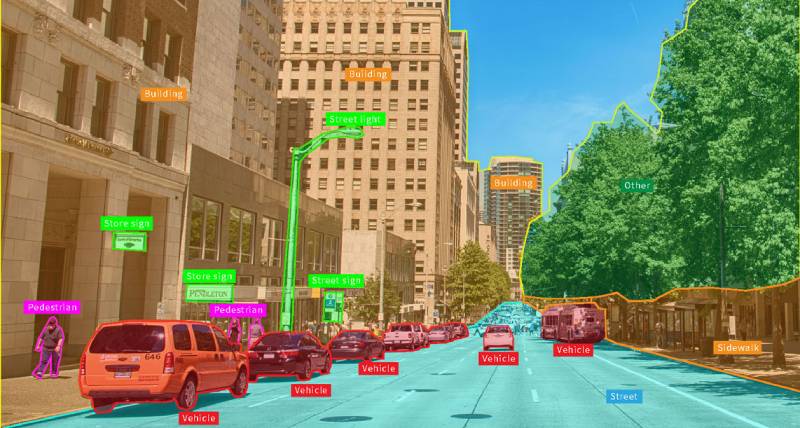
Real-time object detection and image recognition are crucial for self-driving cars. TensorRT can optimize deep learning models for these tasks, enabling vehicles to perceive their surroundings and react swiftly, improving safety and performance.
Medical Imaging Analysis
TensorRT can accelerate medical image analysis applications like cancer detection or anomaly identification in X-rays. This allows for faster diagnoses and potentially life-saving interventions.
Recommendation Systems
Powering the suggestions you see on e-commerce platforms or streaming services often relies on complex deep learning models. TensorRT can optimize these models for real-time personalization, delivering more relevant recommendations to users with lower latency.
Natural Language Processing (NLP)
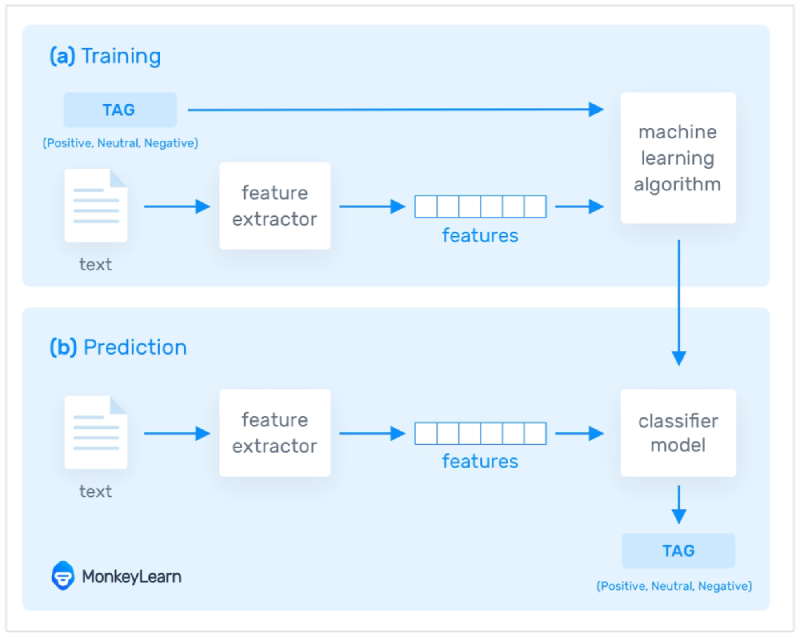
Real-time applications like voice assistants or chatbots leverage NLP models. TensorRT can streamline these models, enabling faster speech recognition, language translation, and more natural interactions.
Robotics
Robots performing tasks in dynamic environments require quick decision-making based on sensor data. TensorRT can optimize deep learning models used for object recognition, obstacle avoidance, and path planning, leading to more agile and responsive robots.
What is the Difference between PyTorch and TensorRT?
When it comes to deploying deep learning models, understanding the differences between frameworks like PyTorch and TensorRT can help you make informed decisions about which tool best suits your needs.
PyTorch

PyTorch is a versatile deep learning framework used for training and developing neural networks. It provides a user-friendly interface for building and manipulating models, making it popular for research and prototyping.
TensorRT
TensorRT is an inference optimizer and runtime library. It takes pre-trained models, typically created in frameworks like PyTorch, and optimizes them for high-performance inference on NVIDIA GPUs.
To sum up, PyTorch is primarily used for model development and training. Whereas TensorRT focuses on model optimization and deployment.
Conclusion
TensorRT offers a compelling solution for overcoming the performance bottleneck often encountered when deploying deep learning models in real-world applications.
By optimizing models for NVIDIA GPUs, TensorRT unlocks significant speed and efficiency gains.
From self-driving cars to medical diagnostics, the potential use cases for TensorRT are vast and continue to expand. So, if you're looking to unleash the full power of your deep learning models, consider adding TensorRT to your deep learning toolkit.