What is Inference in Machine Learning & How Does It Work?


Machine learning inference enables models to make predictions and decisions based on the data they have been trained on. Understanding what machine learning inference is fundamental for grasping the full scope of AI applications.
So in this post, you will learn everything there is to know about machine learning inference. We'll also learn about some common machine learning inference challenges and how to overcome them.
What is Inference in Machine Learning?
Machine learning inference is the process where a trained machine learning model applies its learnings to new data in order to make predictions or decisions.
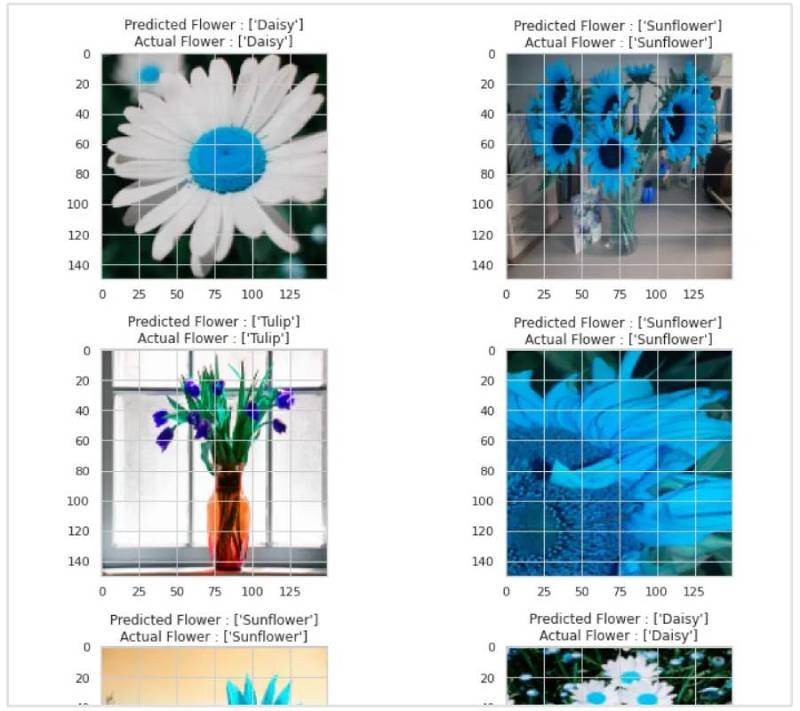
Imagine you've trained a computer program to recognize different types of flowers based on a massive dataset of pictures.
Source: Medium
The training process is like teaching your program all the different features of each flower – its color, shape, petal count, and so on. Machine learning inference is what happens when you show your program a completely new picture of a flower it's never seen before.
During inference, the program uses the knowledge it gained from training to analyze the new picture and predict what kind of flower it is.
In essence, inference is where the rubber meets the road – it's where your trained machine learning model takes that knowledge and puts it to work in the real world by making predictions on fresh data.
What is Inference vs Training in Machine Learning?
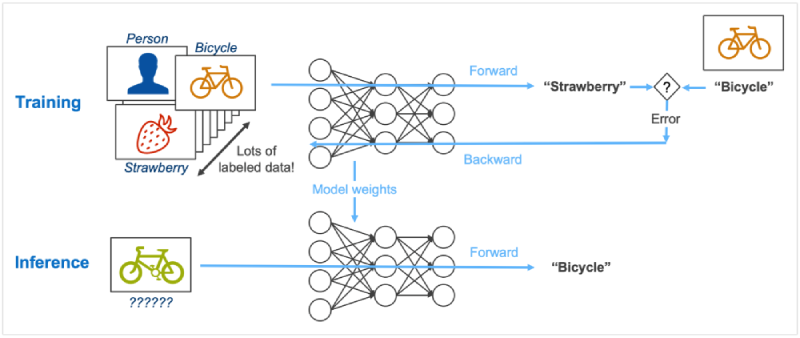
When we talk about machine learning inference versus training, it's like comparing two different phases.
Source: LinkedIn
Let's break it down for you:
- Training: This is where the machine learns from the examples or data it's given. It's like attending classes to understand how things work.
- Inference: Now, think of inference as applying what the machine has learned during training to new situations. It's like using the knowledge gained in class to solve real-world problems.
In a nutshell, machine learning training is the learning phase, while inference is the action phase where the machine puts its learning to practical use.
Let's take our example of the flower recognition program.
During the training phase, you're feeding your machine learning model tons of data and images about flowers so that it can understand all the features that separate a rose from a daisy.
In machine learning inference, the program is presented with a never-before-seen flower picture. Based on all the training data it absorbed, it uses its knowledge to make an educated guess about what kind of flower it is.
Types of Inference in Machine Learning
Batch Inference
This approach involves processing data in groups or "batches." Imagine grading a stack of exams – you wouldn't grade each one individually. Similarly, batch inference accumulates a set of data points and then runs the predictions on the entire batch at once.
This is efficient for tasks where immediate response isn't critical, but large volumes of data need processing.
Real-Time Inference
This is all about speed. Real-time inference makes predictions on individual data points as they arrive, one after another.
Think of analyzing a live video feed for suspicious activity. Here, each frame of video is a data point requiring an immediate prediction.
Or think of your bank using AI for fraud detection. The bank needs to flag suspicious transactions in real-time in order to prevent fraudsters from stealing customer's deposits.
As you can see, real-time inference is essential for applications that need instant results.
Causal Inference in Machine Learning
Causal inference in machine learning focuses on understanding cause-and-effect relationships from observed data.
Machine learning inference often focuses on correlation, meaning it identifies relationships between variables. We know that variable A often appears alongside variable B, but can we say that A causes B?
This is where causal inference comes in.
It aims to determine the impact of a specific factor on an outcome by accounting for potential variables.
Let's consider a scenario in e-commerce where a company wants to determine the impact of a website redesign on user engagement.
By applying causal inference, the company can evaluate whether the increase in user engagement metrics, such as time spent on the site or conversion rates, can be attributed directly to the website redesign rather than external factors like seasonal trends or marketing campaigns.
This analysis can provide valuable insights for optimizing future website changes and marketing strategies based on causal relationships identified through data-driven decision-making.
Advantages of Causal Inference in Machine Learning
- Identifying Causality: Enables businesses to pinpoint the true drivers of outcomes, leading to more informed decision-making.
- Reducing Bias: Helps mitigate biases in observational data, providing more accurate insights.
- Predictive Power: Enhances predictive models by incorporating causal relationships, boosting their performance.
- Strategic Planning: Facilitates strategic planning by highlighting actionable causal factors that drive desired outcomes.
Bayesian Inference in Machine Learning
Bayesian inference is a method in machine learning that involves updating our beliefs about a hypothesis as new evidence or data becomes available. It combines prior knowledge with observed data to make predictions and decisions.
Imagine you're trying to predict the weather for the weekend. With Bayesian inference, you start with a prior belief, like historical weather patterns, and then update this belief as you receive new data, such as current temperature readings.
By combining prior knowledge with real-time data, Bayesian inference helps refine your weather prediction.
Advantages of Bayesian Inference in Machine Learning
- Incorporating Prior Knowledge: Bayesian inference allows us to incorporate existing knowledge or beliefs into our decision-making process.
- Flexible and Adaptable: It can adapt quickly to new information, making it suitable for dynamic environments.
- Probabilistic Framework: Provides uncertainty estimates in predictions, offering a more nuanced understanding of the data.
- Effective in Small Data Settings: Bayesian methods perform well even when data is limited, making them valuable in various scenarios.
How Does Machine Learning Inference Work?
Machine learning inference operates on the foundation of complex algorithms and statistical models that enable machines to make decisions autonomously.
Here's a simplified breakdown of how it works:
Input Data: The process begins with the input data, which is fed into the trained model for analysis.
- Model Application: The model processes the input data using the knowledge gained during training to generate predictions or classifications.
- Decision-making: Based on the processed data, the model makes decisions or predictions without human intervention.
- Output: Finally, the model produces an output that reflects its decision-making process, providing valuable insights or actions based on the input data.
It's important to remember that inference is a probability game. The model doesn't magically "know" the answer – it analyzes the data and gives you the most likely outcome based on its training.
Next, we'll explore some of the challenges associated with this probabilistic nature.
Machine Learning Inference Challenges
While machine learning inference is powerful, it's not without its hurdles. Here are some common challenges faced when putting trained models into action:
Latency
How fast can the model make predictions? This is crucial for real-time applications. Latency refers to the time it takes for a model to receive new data and generate a prediction.
For real-time applications like self-driving cars, high latency can be disastrous. If the model takes too long to process sensor data and decide on a course of action, the car might not react fast enough to avoid a collision.
There are several factors that contribute to latency in machine learning inference:
- Model complexity: Large, complex models with many layers and parameters often require more computational power to run, leading to slower predictions.
- Hardware limitations: The processing power of the hardware running the model (CPU, GPU) can limit how quickly it can perform calculations.
- Data pre-processing: The time it takes to prepare the new data for the model (resizing images, converting formats) can add to the overall latency.
To mitigate latency challenges in machine learning inference, several strategies can be implemented:
- Optimized Algorithms: Utilize efficient algorithms and models that prioritize speed without compromising accuracy.
- Hardware Acceleration: Employ specialized hardware like GPUs or TPUs to accelerate the inference process.
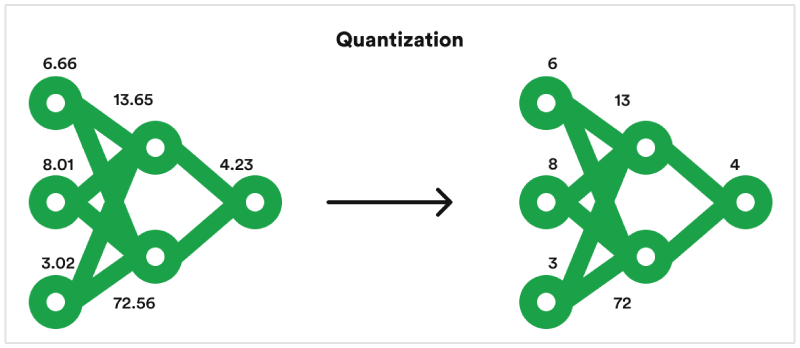
- Model Compression: Reduce the size of models through techniques like pruning or quantization to speed up inference.
- Batch Processing: Process data in batches rather than individually to minimize processing time.
- Caching: Cache intermediate results to expedite future inference tasks and reduce computation overhead.
Scalability
Scalability represents a crucial challenge in machine learning inference as organizations encounter difficulties when scaling AI models to handle increasing data volumes and user demands.
As the complexity and size of models grow, traditional computing resources may struggle to efficiently process inference tasks at scale, leading to performance bottlenecks and diminished system responsiveness.
Here are some strategies to ensure your machine learning inference scales effectively:
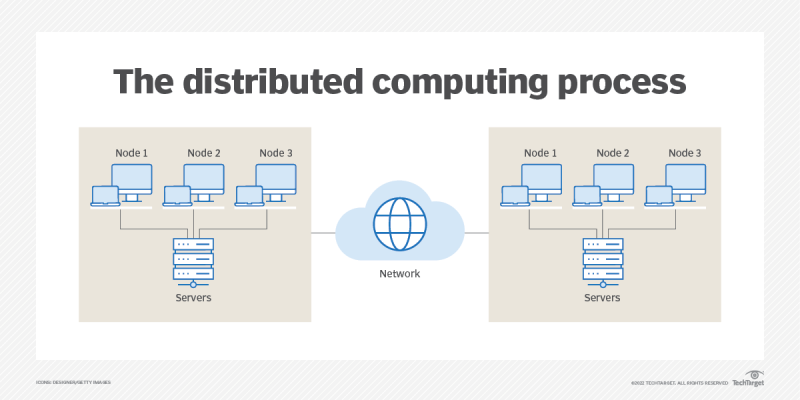
- Distributed computing: Distributing the inference workload across multiple machines or servers can significantly improve processing power and handle large data volumes.Cloud platforms often offer scalable computing resources that can be easily adjusted based on demand.
- Model compression: Techniques like quantization and knowledge distillation can reduce a model's size while maintaining accuracy. Smaller models require less computational power and memory, making them more scalable for deployment.
- Model selection: For certain tasks, simpler, less resource-intensive models might be sufficient. Carefully choosing a model that balances accuracy with efficiency can be crucial for scalability.
- Auto-scaling infrastructure: Cloud platforms offer auto-scaling features that can automatically allocate resources based on real-time demand. This ensures your infrastructure scales up or down as needed, optimizing costs and maintaining performance.
Accuracy
How reliable are the model's predictions in real-world scenarios?
The accuracy challenge in machine learning inference arises due to the need for models to make precise and reliable predictions.
Inaccurate predictions can lead to incorrect decisions, impacting user experience, business outcomes, and overall trust in the AI system.
Achieving high accuracy is crucial, especially in critical applications like healthcare diagnostics or financial forecasting.
To enhance accuracy in machine learning inference, consider the following strategies:
- Quality Data: Ensure high-quality, diverse, and representative training data to improve model generalization and accuracy.
- Hyperparameter Tuning: Fine-tune model parameters to optimize performance and increase accuracy on validation datasets.
- Ensemble Methods: Combine predictions from multiple models using ensemble techniques like bagging or boosting to improve overall accuracy.
- Regularization: Apply regularization techniques to prevent overfitting and enhance model generalization, ultimately boosting accuracy.
- Cross-Validation: Implement cross-validation methods to assess model performance robustness and ensure reliable accuracy estimates across different datasets.
Interpretability
Interpretability refers to our ability to understand how a machine learning model arrives at its predictions.
Interpretability poses a significant challenge in machine learning inference as complex AI models often operate as "black boxes," making it difficult for users to comprehend the reasoning behind their decisions.
Understanding how models reach conclusions is crucial for users to validate predictions, detect biases, and ensure fair decision-making.
To address the challenge of interpretability in machine learning inference, consider the following strategies:
- Choosing interpretable models: Certain types of machine learning models, like decision trees or rule-based models, are inherently easier to interpret than complex neural networks.
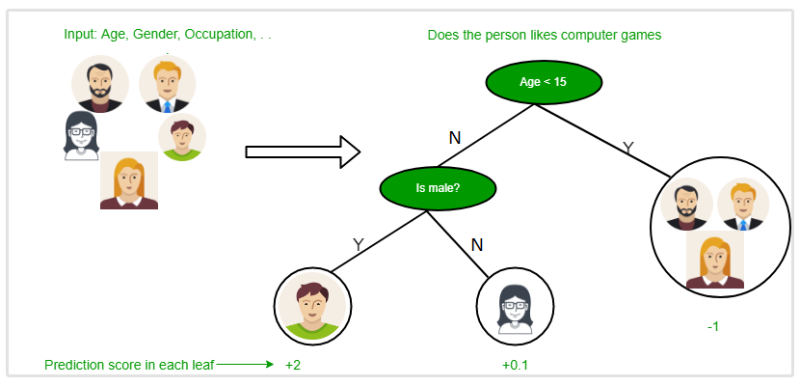
- Explainable AI (XAI) techniques: These methods aim to explain the inner workings of a model by providing insights into how different features contribute to the final prediction. Techniques like LIME (Local Interpretable Model-agnostic Explanations) can help visualize how a model interprets a particular data point.
- Feature importance analysis: By understanding which features in the data have the most significant influence on the model's predictions, we can gain insights into its decision-making process.
Resource Constraints
Resource constraints present a significant challenge in machine learning inference as AI models often require substantial computational resources to perform complex computations efficiently.
Limited access to computing power, memory, or storage can hinder the speed and scalability of inference tasks, impacting the overall performance and effectiveness of AI systems.
Resource constraints can impede real-time decision-making, delay responses, and restrict the deployment of large-scale models in resource-constrained environments.
Here are some strategies to overcome resource constraints in machine learning inference:
- Model optimization techniques: Techniques like pruning, quantization, and knowledge distillation can significantly reduce the size and computational demands of a model without sacrificing too much accuracy. This allows you to run the model on devices with limited resources.
- Efficient hardware utilization: Utilizing specialized hardware like mobile GPUs or edge computing devices specifically designed for low-power machine learning inference can improve performance on resource-constrained environments.
- Model selection: For certain tasks, choosing simpler, less resource-intensive models from the outset can be crucial for successful deployment on devices with limited resources.
Conclusion
Machine learning inference takes machine learning models from theory to practice. It's the process where trained models analyze new, unseen data and generate predictions.
In this post, we explored the key differences between inference and training, along with the various challenges that arise when putting these models into action.
We also looked at how to address these challenges through optimization techniques, hardware advancements, and thoughtful model selection.
By understanding the intricacies of machine learning inference, developers can build robust and reliable models that have the potential to transform industries and shape our everyday experiences.