14 Commonly Asked Interview Questions for Data Engineers


Getting a job as a data engineer can be the next big step in your tech career.
However, with stiff competition in the tech industry, companies select only the best candidates.
By thoroughly preparing for and acing your interview, you can put the odds in your favour for getting that data engineer job.
In this blog post, we will help you prepare with this list of interview questions for data engineers.
We'll also share some tips on how you can prepare for a data engineer interview so that you can be more confident beforehand.
The interview questions for a data engineer job tend to be heavily focused on the technical aspects of the role, however, it's always a good idea to prepare for the non-technical questions too.
Let's start with the more general data engineer interview questions which include questions about soft skills such as communication, team work, and more.
Then we'll move to the more technically oriented interview questions for data engineers.
But before we begin, did you know that AI Jobs has got hundreds of data engineering jobs from some of the top tech companies? Feel free to check out all of the available positions, and apply directly on our site if you meet the criteria.
General Data Engineer Interview Questions
Can you tell me more about yourself?
This is one of the first questions you are likely to encounter in your interview.
By asking you to talk about yourself, the hiring manager aims to get to know you beyond your resume. They want to understand your background, experiences, and what drives you professionally.
This question also serves as a tool for determining whether you're a good fit for the job and the company's culture.
Why did you choose a career in data engineering?
This question helps interviewers gauge your genuine interest and passion for the field, as well as your understanding of the role's importance. They want to see if your motivations align with the job responsibilities and the company's goals.
When answering this question, it's important that you highlight your passion for data science.
You could mention specific aspects of data engineering that excite you, such as data modelling, ETL processes, or cloud technologies.
What is a data engineer's role within an organization?
This next question aims to assess your understanding of the data engineer's responsibilities and their impact on the company. Interviewers want to ensure that you have a clear grasp of how your role contributes to the organization's overall data strategy and business objectives.
Here's a sample answer that showcases a solid understanding of a data engineer's role:
The role of a data engineer within an organization is important for managing and optimizing the flow of data from various sources to ensure it is accessible, reliable, and high-quality. Data engineers are responsible for designing, constructing, and maintaining scalable data pipelines that collect, process, and store data efficiently.
Describe a challenging data engineering project you worked on and how you overcame them
Recruiters and hiring managers want to see how you handle complexity and adversity, and how you apply your skills in real-world scenarios.
This question is commonly asked in all interviews to assess a candidate's problem-solving ability.
When answering this question, you need to have a logical layout or "storyline", here's a great structure for formulating your response:
- Context: Briefly describe the project and its objectives.
- Challenge: Detail the specific challenge you faced.
- Action: Explain the steps you took to address the issue.
- Result: Highlight the positive outcome of your actions.
By structuring your answer effectively, you provide a comprehensive and compelling narrative that showcases your problem-solving skills, technical proficiency, and ability to deliver impactful results.
Why should we hire you?
This question is often asked at the very end of your interview and serves as a final opportunity for candidates to "sell" themselves and make a lasting impression.
Interviewers use this moment to evaluate your confidence, self-awareness, and ability to articulate why you are the best fit for the role.
To answer this question effectively, consider the following:
- Summarize Key Strengths: Highlight your most relevant skills and experiences that align with the job requirements.
- Showcase Unique Selling Points: Mention qualities or achievements that set you apart from other candidates.
- Align with Company Needs: Demonstrate your understanding of the company's challenges and how you can contribute to solving them.
- Express Enthusiasm: Convey your excitement about the role and the organization.
Technical Questions for Data Engineer Interview
Now that we've covered the general interview questions for data engineers, let's move to the technical questions.
Remember, data engineering is a practical field, you'll really need to impress the interviewer with your knowledge on all things technical.
What data visualization tools have you used?
This question just tests your familiarity with popular and effective tools in the industry. Here's a list of data visualization tools that data engineers typically use:
- Tableau
- Power BI
- D3.js
- QlikView
- Google Looker Studio
You might also need to be prepared to state which of these data visualization tools are your favourite and why.
What's the difference between a data warehouse and an operational database?
The first technical data engineer interview question deals with one of the core principles of data science.
Understanding the distinction between a data warehouse and an operational database is quite important for any data engineer.
While both store data, data warehouses and operational databases serve distinct purposes.
Operational databases are optimized for fast transactions, like processing customer orders or managing inventory. They typically hold current data and prioritize speed and data integrity.
Data warehouses, on the other hand, are designed for data analysis. They house historical data from various sources, often structured for complex queries and insightful reports. Speed is less crucial here compared to the ability to analyse vast amounts of data.
What is data modelling?
Data modelling is the process of creating a blueprint for organizing and structuring data.
In an interview, be prepared to discuss different data modelling techniques (e.g., relational, dimensional) and how they apply to building data warehouses or designing efficient data storage solutions.
In addition to being able to explain data modelling techniques, you should also be able to explain the following:
- Concepts: Understand entities, attributes, and relationships.
- Types: Differentiate between conceptual, logical, and physical data models.
- Tools: Familiarize yourself with tools like ER/Studio, IBM InfoSphere Data Architect, or MySQL Workbench.
- Best Practices: Emphasize the importance of consistency, scalability, and performance optimization.
Can you tell me the difference between structured and unstructured data?
The ability to distinguish between structured and unstructured data is a key skill for data engineers.
Structured data is highly organized and easily searchable data stored in predefined formats, typically in rows and columns. Whereas unstructured data lacks a predefined format or organization, making it more complex to process and analyse.
You can then take it a step further by explaining how you would transform unstructured data to structured data.
What are the two design schemas in data modelling?
In data modelling, there are two prevalent design schemas specifically used in data warehouses for optimized querying and data analysis, namely, star schema and snowflake schema.
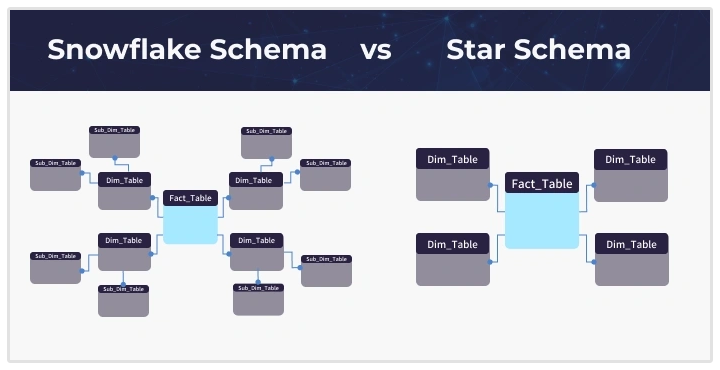
The star schema features a central fact table containing quantitative data (metrics) and keys to dimension tables, which store descriptive attributes related to the facts, such as time, product, or customer.
This structure enhances query performance due to fewer joins, making it easier to understand and implement. It is ideal for straightforward, fast-access querying, commonly used in data warehousing and business intelligence.
Conversely, the snowflake schema employs a more complex, normalized structure where dimension tables are further split into related sub-dimension tables. This design schema is better suited for handling intricate, hierarchical relationships within data.
What do *args and **kwargs mean? Can you tell me the difference?
Recruiters and interviewers often ask about *args and **kwargs to gauge a candidate's understanding of Python's flexible function parameters.
These concepts are fundamental for writing functions that can handle varying numbers of arguments, which is crucial in data engineering for creating reusable, scalable, and efficient code. This question helps determine if the candidate has a solid grasp of Python's capabilities and can apply this knowledge to real-world problems, such as data processing pipelines or API development.
In Python, *args and **kwargs allow functions to accept a variable number of arguments. The *args syntax lets a function take any number of positional arguments, packing them into a tuple.
On the other hand, **kwargs allows a function to accept any number of keyword arguments, packing them into a dictionary.
What are the four V's of big data?
When it comes to big data, there's a common framework used to describe its defining characteristics: the four V's.
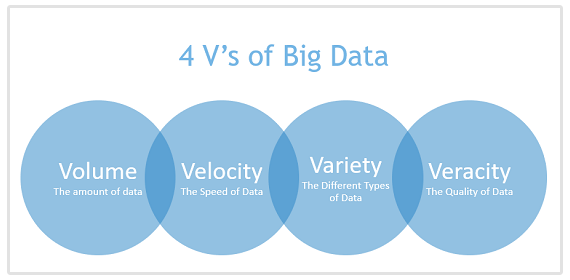
Understanding these V's is essential for data engineers, as they grapple with the challenges and opportunities presented by massive datasets. Here's a breakdown of each V:
- Volume: This refers to the sheer amount of data being generated today. Data engineers need to design and manage systems that can ingest, store, and process these vast quantities of information.
- Velocity: This highlights the speed at which data is generated and needs to be processed. With the rise of real-time applications and internet of things (IoT) devices, data is constantly flowing in. Data engineers need to build pipelines that can handle this high velocity of data flow to ensure information is available for analysis close to real-time.
- Variety: Data engineers need to be comfortable working with this variety of data formats to extract meaningful insights.
- Veracity: This V emphasizes the importance of data accuracy and trustworthiness. With so much data floating around, ensuring its quality is crucial. Data engineers play a vital role in implementing data cleansing techniques and data governance strategies to guarantee the accuracy and reliability of the data used for analysis.
Which Python libraries are best for data processing and analysis?
When it comes to data processing and analysis, Python offers a rich ecosystem of libraries that are widely used in data engineering.

Below are some of the most commonly used Python libraries in this field:
- NumPy: The foundation for numerical computing in Python. It offers efficient multidimensional arrays and linear algebra operations, making it crucial for data manipulation.
- Pandas: A superstar library built on top of NumPy, specifically designed for data analysis. It provides high-performance data structures like DataFrames for easy data manipulation, cleaning, and analysis.
- SciPy: This library extends NumPy's capabilities with advanced scientific computing algorithms for tasks like optimization, integration, and statistical analysis.
- Matplotlib: A versatile library for creating static, animated, and interactive visualizations of data. It offers a wide range of plot types and customization options.
Of these libraries, Pandas is likely the most commonly used Python library. Its DataFrames provide a powerful and intuitive way to work with tabular data, making it a favourite among data engineers for its speed, flexibility, and rich ecosystem of data analysis tools.
How would you deal with duplicate data in SQL?
Recruiters often ask about handling duplicate data in SQL because it's a common challenge faced by data engineers.
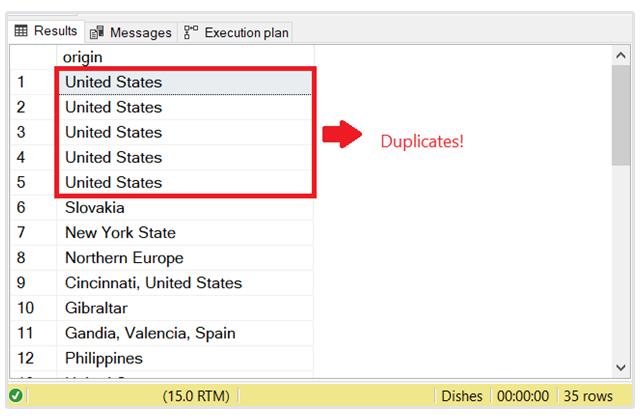
There are several ways to tackle duplicates in SQL, and interviewers are looking for your understanding of these techniques.
One common approach is using the SELECT DISTINCT clause to retrieve only unique rows from a table. For removing duplicates altogether, you can employ DELETE statements with GROUP BY and HAVING clauses to identify and delete rows with duplicate values.
How to Prepare for a Data Engineer Interview
Preparing for a data engineer interview involves more than just formulating answers to technical questions.
Here are some additional ways to prepare and impress your potential employers:
Understand the Job Description
Carefully review the job posting to understand the specific skills and experiences the employer is seeking.
Try to tailor your preparation to highlight your relevant qualifications and experience that aligns with what the job description says.
Brush Up on Fundamentals
Ensure you have a strong grasp of core concepts such as SQL, data modelling, ETL processes, and big data technologies.
Revisit any areas where you feel less confident. Remember, the more prepared you are, the more confidently you can answer all the technical questions coming your way in the interview.
Hands-On Practice
Engage in practical exercises using real datasets.
Platforms like Kaggle, LeetCode, or building your own projects can help reinforce your skills and demonstrate your capability to handle real-world scenarios.
Review Common Tools and Technologies
Familiarize yourself with the tools and technologies commonly used in data engineering, such as Apache Hadoop, Spark, Kafka, and cloud platforms like AWS, Azure, or Google Cloud.
Mock Interviews
Conduct mock interviews with someone you know.
This practice helps reduce anxiety and improves your ability to articulate your thoughts clearly and confidently.
Know the Company
Research the company’s industry, recent news, and the challenges they face. Understanding the company’s context allows you to tailor your answers to show how you can address their specific needs.
Prepare Questions
Have insightful questions ready for the interviewer. This demonstrates your genuine interest in the role and helps you assess if the company is the right fit for you.
Some examples of questions that you can ask include:
- What are the working hours?
- Annual number of paid leave days
- Is the role fully remote or on-site?
- What do you expect of me?
- What growth opportunities can I expect if I work here?
- Why should I choose this company over any of your competitors?
Are Data Engineers in Demand?
Yes, data engineers are in high demand.
The ever-increasing volume of data generated across all industries has created a pressing need for skilled data engineers who can manage, process, and transform data into actionable insights.
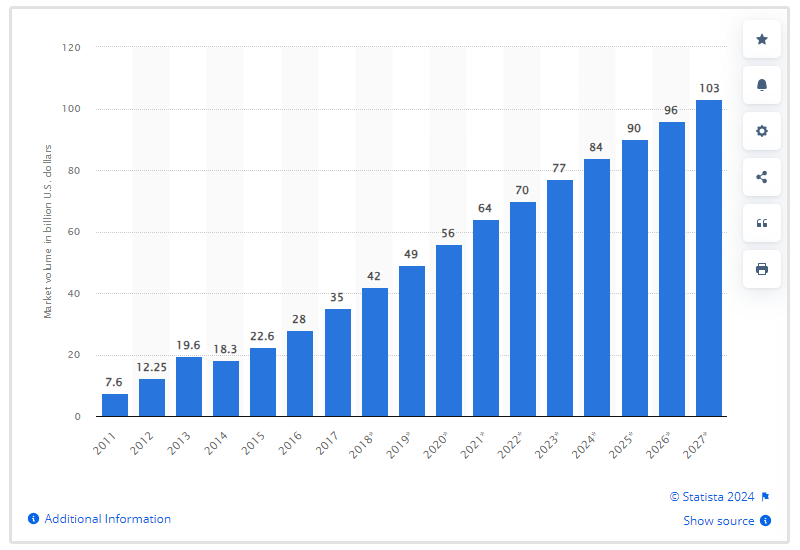
With the global big data market expected to reach $103 billion by 2027, companies are investing heavily in data infrastructure, fuelling the need for data engineers to design and maintain these systems.
What Does a Data Engineer Do?
A data engineer plays a crucial role in managing and optimizing the flow of data within an organization.
Their day typically involves a series of tasks designed to ensure that data is easily accessible, reliable, and actionable for decision-makers.
Here are some common tasks that a data engineer does during their day:
- Designing Data Architectures: Crafting and maintaining data pipelines and architectures that efficiently manage the ingestion, processing, and storage of large datasets.
- ETL Processes: Developing Extract, Transform, Load (ETL) workflows to aggregate data from various sources, clean it, and prepare it for analysis.
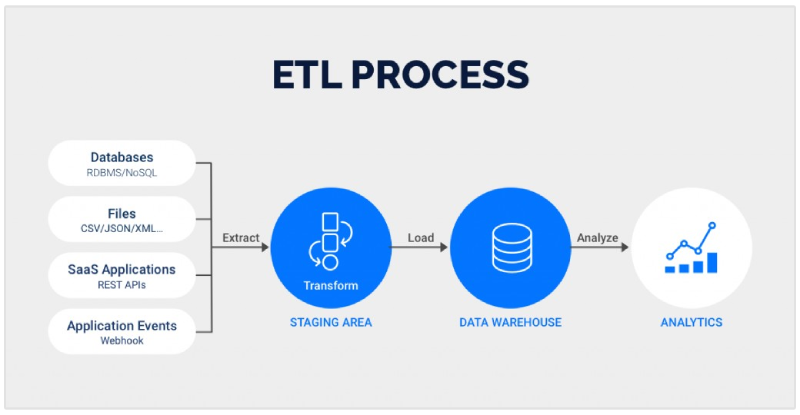
- Database Management: Managing database systems (e.g., SQL, NoSQL) to ensure they are performing optimally, which includes tuning databases for speed and reliability.
- Data Integration: Integrating diverse data sources, including APIs, cloud services, and on-premises systems, to create a unified data ecosystem.
- Ensuring Data Quality: Conducting regular data validation and cleansing processes to maintain high data quality and integrity.
- Collaboration: Working closely with data scientists, analysts, and other stakeholders to understand their data needs and provide support for analytics and reporting tasks.
- Performance Optimization: Continuously monitoring and improving data processing performance, which may involve optimizing queries, updating hardware, or refining algorithms.
- Documentation: Creating detailed documentation for data processes, architectures, and schemas to facilitate knowledge sharing and future maintenance.
How Many Stages are There in a Data Engineer Interview?
In most cases, you will need to go through several rounds of interviews for a data engineer position.
Each stage is designed to assess different aspects of your skills and fit for the role.
Also take note, each company has their own way of doing things, so the number of interview rounds will differ from company to company.
Initial Screening (Phone or Video Call)
This is a preliminary conversation with an HR representative or recruiter. It's your chance to introduce yourself, discuss your qualifications, and learn more about the role and company culture.
Technical Phone Screen
If you impress in the initial screening, a technical phone screen with a data engineer or a team lead might follow.
This dives deeper into your technical skills, with questions on SQL, data structures, big data concepts, and potentially some basic coding challenges.
Coding Challenge or Take-Home Assessment
Many companies use coding challenges or take-home projects to evaluate your programming abilities and problem-solving approach.
These challenges can involve building a data pipeline, writing data transformation scripts, or analysing a specific dataset.
On-Site Interviews
If you pass the previous stages, you'll likely get invited for on-site interviews. This typically involves multiple rounds, with each focusing on different aspects.
Expect technical interviews with senior data engineers or the hiring manager, where they'll assess your in-depth knowledge of data engineering principles, big data technologies, and your experience handling complex data challenges.
You might also have to answer some behavioural questions to gauge your teamwork, communication, and problem-solving skills.
Final Round and Offer
After the on-site interviews, there might be a final round with the hiring manager or senior leadership to discuss your candidacy and salary expectations. If everything aligns, you'll receive the exciting news of a job offer.
Wrapping Up
The questions we addressed in this blog post will give you a solid foundation to work from in preparing for your data engineering interview.
By formulating your own answers to these questions and preparing beforehand, you'll come across as confident and it'll be easier to make a good impression with your interviewer.