13 Computer Vision Interview Questions with Answers


Being prepared for an interview in computer vision is essential if you want to make a good impression and improve your chances of getting the job.
By knowing beforehand the most common computer vision interview questions, you'll be able to answer the interviewer's questions with confidence.
In this post, we're going to list 13 computer vision interview questions with answers that you can use in your preparation for your interview.
But first, what exactly does a computer vision engineer do?
What Does a Computer Vision Engineer Do?
A computer vision engineer specializes in developing algorithms and technologies that enable machines to interpret, analyze, and understand visual information from the surrounding environment.
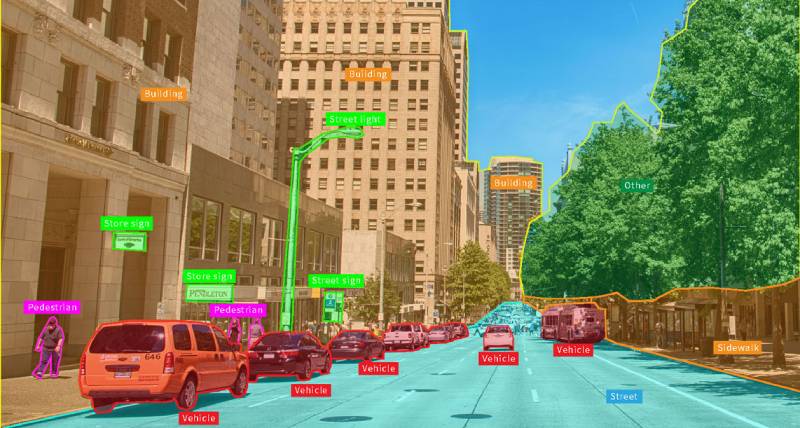
Source: Appen
The core idea is to create systems that can replicate human vision capabilities, this includes object recognition, image processing, and pattern detection.
Computer vision engineers design and implement solutions for various applications like autonomous vehicles, facial recognition systems, medical image analysis, and augmented reality.
Now that you’ve got a general idea of what exactly a computer vision engineer does, let's move on to answering some of the most commonly asked computer vision engineer interviews.
Note: let the answers serve as a guide during your preparation for your interview. So don't copy the answers that we're giving here.
13 Computer Vision Engineer Interview Questions
1. What is the difference between image classification and object detection?
Image classification involves categorizing an entire image into a specific class or category, assigning a single label to the entire image.
On the other hand, object detection goes a step further by not only identifying the main object in an image but also outlining the location of multiple objects within the image by drawing bounding boxes around them.
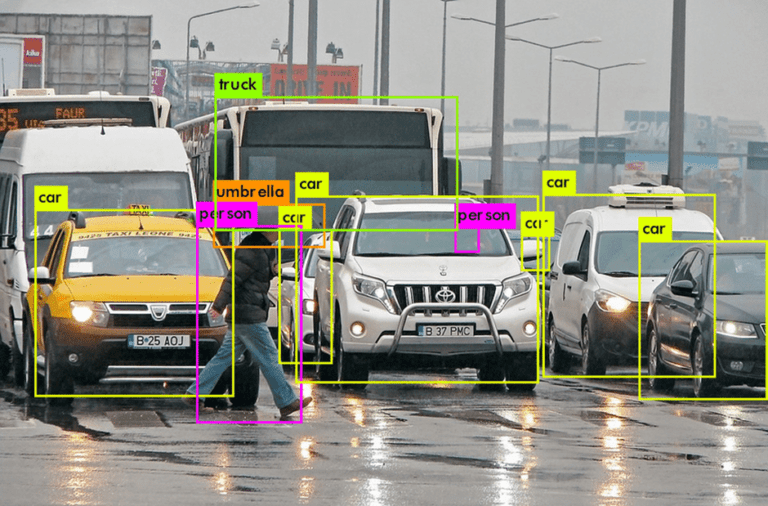
So for instance, image classification tells us if an image is a cat, a dog, or a landscape. Object classification tells us if there's a cat in the top left corner and a car in the background.
2. What are some common image pre-processing techniques used in computer vision?
In computer vision, we often use pre-processing techniques to get images ready for analysis by algorithms.
Here are a few common ones:
- Resizing and Rescaling: Adjusting images to a standard size for consistency.
- Normalization: Standardizing pixel values to a common scale for better model performance.
- Grayscale Conversion: Converting colored images to grayscale for simplification.
- Noise Reduction: Removing noise to improve image clarity.
- Image Augmentation: Generating new training samples by applying transformations like rotation, flipping, and zooming.
- Histogram Equalization: Enhancing contrast in images for better feature extraction.
- Edge Detection: Identifying edges to highlight object boundaries.
- Blur Filtering: Smoothing images to reduce high-frequency noise.
3. Describe convolutional neural networks (CNNs) and their role in computer vision.
Convolutional Neural Networks, or CNNs, are a type of deep learning architecture that excel at image recognition tasks.
They're inspired by the structure of the human visual cortex.
CNNs consist of convolutional layers that use filters to extract features from images like edges, lines, and shapes. These features are then processed by pooling layers that reduce dimensionality and capture the most important information.
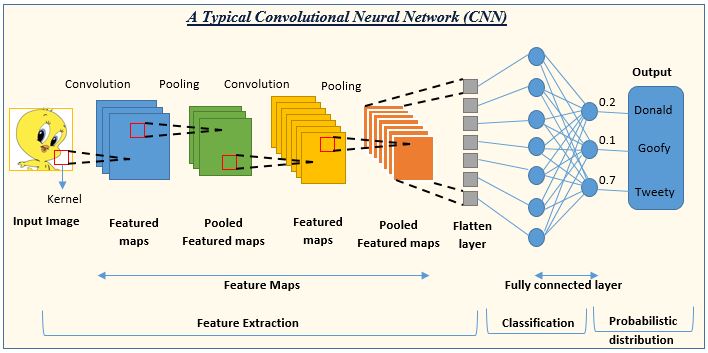
Through multiple convolutional and pooling layers, CNNs can progressively learn complex features that ultimately allow for object recognition, image classification, and other computer vision applications.
4. Can you compare supervised and unsupervised learning in the context of computer vision?
Supervised learning involves training a model using labeled data, where input images are paired with corresponding output labels.
It requires human intervention to provide correct answers during training. And is ideal for tasks like image classification and object detection where the algorithm learns from labeled examples.
Unsupervised learning focuses on finding hidden patterns or intrinsic structures in unlabelled data without explicit guidance.
This form of learning does not rely on predefined labels, allowing the model to discover patterns independently. Unsupervised learning is best suited for tasks like clustering similar images or anomaly detection in images based on inherent similarities or differences.
5. How do you handle overfitting in deep learning models for computer vision tasks?
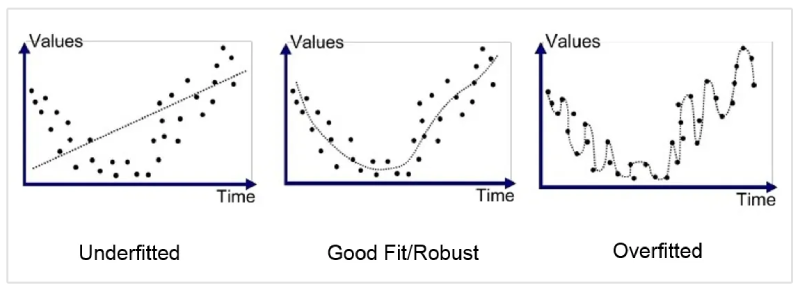
Overfitting is a common challenge in computer vision tasks with deep learning models. Here are some ways to tackle it:
- Data Augmentation: Artificially increasing the size and diversity of your training data through techniques like random cropping, flipping, or color jittering can help the model generalize better and reduce reliance on specific features in the original dataset.
- Regularization: Adding a penalty term to the loss function discourages the model from learning overly complex patterns in the training data. Techniques like L1/L2 regularization or dropout layers can help achieve this.
- Early Stopping: Monitor the model's performance on a validation set during training. Stop training when the validation accuracy plateaus or starts to decrease – this indicates the model is memorizing the training data instead of learning generalizable features.
- Reducing Model Complexity: If overfitting persists, consider using a simpler model architecture with fewer layers or parameters. This can help prevent the model from becoming overly specialized on the training data.
6. Describe your experience with computer vision libraries like OpenCV or TensorFlow.
OpenCV is a comprehensive open-source library that provides a wide range of functions for image processing, video analysis, and real-time computer vision tasks. It offers a user-friendly interface and supports various programming languages, making it a popular choice for prototyping and developing computer vision applications.
TensorFlow is a powerful open-source framework for building and deploying machine learning models.
While more general-purpose, it's particularly well-suited for deep learning tasks in computer vision, like image classification, object detection, and image segmentation. Its flexibility allows for building custom models and leveraging hardware acceleration for faster training and inference.
A hiring manager might ask about your experience with these libraries to gauge your familiarity with industry-standard tools.
7. How do you handle occlusions and variations in lighting conditions in object detection?

Occlusions and lighting variations are tricky in object detection! Here's how we can tackle them:
- Data Augmentation: We can artificially introduce occlusions and lighting variations in our training data (faking shadows, dimming images). This exposes the model to these challenges and improves its ability to handle them in real-world scenarios.
- Advanced Techniques: For tougher cases, techniques like deformable part models or keypoint estimation can help account for occluded or partially visible objects.
I tend to ask a lot of situational questions like this during computer vision interviews because I find they give me the best sense of how the candidate will approach their role if hired, and whether they have the type of experience and skill sets that the position demands.
- Rob Boyle, Airswift

8. How would you evaluate the performance of an object detection model?
To evaluate the performance of an object detection model, you can utilize metrics like:
- Precision and Recall: Measuring the model's accuracy in detecting objects and minimizing false positives.
- Intersection over Union (IoU): Calculating the overlap between predicted and ground truth bounding boxes.
- Mean Average Precision (mAP): Assessing the model's overall performance across different object categories.
- F1 Score: Harmonizing precision and recall to gauge the model's effectiveness comprehensively.
9. Explain the concept of non-max suppression in object detection.
Non-max suppression (NMS) is a technique used in object detection to clean up bounding boxes. It removes redundant boxes that likely represent the same object.
Imagine two boxes overlapping a cat.
NMS keeps the box with the highest confidence score (most likely the cat) and suppresses the others. This helps improve the accuracy and precision of your detections.
10. Discuss a recent advancement in the field of computer vision that excites you.
This question gauges your passion for the field and your ability to keep up with the fast-paced advancements in computer vision. It shows the interviewer you're actively engaged and interested in the latest developments.
To stay updated on recent advancements in computer vision, consider referring to reputable sources such as:
- ArXiv
- Towards Data Science on Medium
- Papers With Code
- Computer Vision News
- IEEE Computer Society - Computer Vision
11. What are your thoughts on the future of computer vision?
The hiring manager might ask about your thoughts on the future of computer vision to assess your understanding of industry trends, your ability to foresee technological advancements, and your capacity to envision how emerging technologies can impact the field.
Demonstrating insight into the future of computer vision can showcase your strategic thinking, adaptability, and foresight in navigating evolving landscapes within the industry.
12. In your opinion, what skills are most important for a successful computer vision engineer?
There are three key skill sets that make a successful computer vision engineer:
- Solid foundation in computer science: This includes strong programming skills, familiarity with data structures and algorithms, and understanding of core computer vision concepts like image processing and computer graphics.
- Machine learning and deep learning expertise: A strong grasp of machine learning concepts and the ability to build and train deep learning models for computer vision tasks are crucial. Experience with libraries like TensorFlow or PyTorch is a big plus.
- Problem-solving and analytical skills: Being able to break down complex computer vision challenges, analyze data effectively, and think creatively to find solutions is essential. Additionally, excellent communication skills are important to explain technical concepts clearly to both technical and non-technical audiences.
13. Walk me through a computer vision project you've worked on.
Recruiters often ask candidates to walk them through a computer vision project to assess their practical experience, problem-solving skills, technical proficiency, and ability to communicate complex concepts clearly.
Remember to Ask Questions Too
Remember that an interview is an opportunity for a candidate to find out more about a potential employer, so alongside their questions, make sure you prepare a set of questions to ask your interviewer.
Having questions prepared beforehand is always useful, particularly as interviews can be daunting or highly pressured environments where we lose our trail of thought.
Aidan Cramer, Founder and CEO at AI Apply suggests that this is an important part of preparing for an interview that is often overlooked.
Not only is it useful to you, but it also shows a potential employer that you’re really keen to find out more about the role or the company you could be working in, demonstrating your passion and willingness to learn.
- Aidan Cramer

So spend some time thinking of thoughtful questions that you can ask at your next computer vision engineer interview.
Conclusion
Now you know some of the most common computer vision interview questions. It's important that you prepare well in advance for this interview so that you can easily and confidently answer the questions a recruiter or hiring manager might ask.